L'étude du contexte, premier niveau conceptuel, permet de relever les données gérées et leur dépendances.
Dans les données traitées, il y a différentes granularités :
un numéro de dossier est une donnée élémentaire alors qu'une adresse est composite (rue+cp+ville).
Une personne est un groupeement informatif encore plus complexe pour le système d'information (je les nomme concepts) car, au-delà de ses données de base (nom, prénom, ...) elle possède aussi des relations avec d'autres concepts.
Avant d'aborder les modèles, on peut déjà relever trois types d'informations qui sont les concepts, les données et les valeurs.
Les concepts sont des choses, des objets que l'on va gérer.
Ils deviendront probablement des entités du schéma entité association du modèle Merise ou des classes de la modélisation UML vus plus loin.
- Les données sont des informations élémentaires, indivisibles, sur les concepts et deviendront des propriétés ou des attributs selon le modèle et le niveau de modélisation.
- Les valeurs sont des occurrences, des exemples de données ou de concepts.
Données et concepts sont souvent masqués par des valeurs de ceux-ci ou exprimés par des euphémismes ou des synonymes.
A noter que :
- l'organisation elle-même n'est pas modélisée mais seulement les partenariats avec d'autres organisations externes.
- Les documents sont seulement des supports d'informations.
- Les données non pertinentes, calculées, etc… ne sont pas modélisées car on pourra les reconstituer avec un algorithme (un calcul).
Valeur
Valeur : c'est un nombre, une date, une chaine de caractères out tout autre valeur qui porte une signification dans le contexte : 123 = numéro de commande, "Marc" = prénom de personne.
Certains concepts ou données sont masqués par des valeurs exposant différentes occurrences de ceux-ci.
Exemples oui :
- 1, 2, sont des nombres élémentaires. Impossible de les diviser (au sens d'information).
- "France-télécom", "Jean-Marc" sont des noms simples
- Strasbourg, Nantes, Rennes, Lyon et Mulhouse sont des occurrences de la donnée 'nom ville', elles-même appartenant à des occurrences du concept 'ville'.
/!\ 32 ans, 50 km sont des valeurs dont la nature de données est apportée par l'unité de mesure associée au nombre (ans=durée, km= distance ou longueur) on aura donc ici deux valeurs : le nombre et l'unité de mesure.
Exemple non :
"type article", "ville" sont respectivement un nom de donnée élémentaire et un nom de concept complexe.
Dans tous les cas, il ne faut relever que les données et concepts pertinents pour l'étude, gérés par le système décrit, et ne pas se laisser perturber par des informations qui constituent le bruit de l'étude.
A noter que les informations sur l'entreprise elle-même ne sont pas à relever, seules les données avec lesquelles on travaille sont à noter.
Exemple descriptif (gescom)
La société StéSIO travaille avec des clients à Strasbourg, Lyon et Nancy.
L'analyse dégage les points suivants :
- StéSIO n'est pas une donnée, c'est la description de l'organisation ;
- Client est un concept (dont on ne sait rien d'autre de son contenu)
- Strasbourg, Lyon, … sont des occurrences de la donnée 'nom ville' du concept 'ville'.
- "À" indique qu'il y a un lien, une association, une relation entre les concepts client et ville
On a donc ici :
- concept : client (données inconnues)
- concept : ville (nom de ville)
- relation : client détermine ville
Donnée
Une donnée est une information élémentaire qui ne peut pas être décomposée et qui représente des valeurs cohérentes.
nom de ville => élémentaire : (Nancy, Sélestat, Lyon, Strasbourg, Paris, Brest, Niederschaeffolsheim, Saint-Remy-en-Bouzemont-Saint-Genest-et-Isson, Y, ...)
"La donnée est définie comme un symbole qui représente, une connaissance sur : un fait, un procédé, une notion, un chiffre, une personne, etc.".
cit. Ontologies et stockage de données (thèse M. Okba Barkat 2017)
Une donnée possède un nom (/ex. : numéro de dossier, nom de personne), un type élémentaire (/ex : chaine de caractère, entier, date, ...) et appartient à un concept plus grand.
Exemple oui :
- description, prix, quantité, numéro d'identification, nom, prénom, ville, code postal, etc. …
Exemple non :
- 123, "toto" : ce sont des valeurs qui illustrent une donnée,
- adresse : l'adresse contient plusieurs données : la rue, le code postal et le nom de la ville. Il faudrait diviser cette donnée.
- fournisseur, article, ingénieur : ils sont complexes, ce sont des concepts qui contiennent des données.
Dans le discours du sujet, une donnée est souvent rattachée à un concept.
Cela permet de relever une relation entre la donnée et le concept.
Exemple oui :
- nom de l'élève,
- nom de la ville,
- description de l'article,
- numéro de commande,
- quantité de l'article dans la commande,
- nom de l'employé, numéro du client, numéro de commande,
- etc. …
Exemple non :
- description (tout court, sans dire ce qui est décrit),
- numéro sans mention : numéro de quoi, de bâtiment, de commande ?
A partir de ce relevé, on rempli un tableau des données trouvées : le dictionnaire des données.
Concept
Un concept est une information, une donnée complexe, qui peut être décomposée en données élémentaires :
personne => nom, prénom, date de naissance, etc. ...
L'une des propriétés ou un groupe de propriétés du concept permet d'identifier chaque donnée du concept qui séparément en dépendent. C'est l'identifiant' unique qui représente chaque groupe de valeurs des propriétés du concept.
C'est un ensemble cohérent de données élémentaires, un agrégat, qui forme une information plus complexe.
Un concept possède toujours des données.
Pour détecter un concept, on va relever :
- les noms de choses, d'objets, de personnes (acteurs externes, rôles),
- de types d'objets ou autres documents supports d'information et objets semi virtuels,
- objets du système d'information, des agrégats de données.
Ce seront souvent des concepts.
Ce seront sûrement des concepts si des données y sont rattachées.
Exemple oui :
- article, commande, client, employé, etc. …
Exemple non :
- description : donnée élémentaire,
- organisation gérée : non modélisée,
- tapis Z7 cendré : valeur d'une donnée (description d'un article).
L'organisation gérée par le SI n'est jamais un concept modélisé dans le SI.
Cependant certains objets gérés qui appartiennent à l'organisation peuvent être modélisés.
Par exemple : les établissements ou sites de production ou lieux de stockage des matériaux => données = nom, adresse, code lieu, coordonnées géographiques ...
Dépendance fonctionnelle
Une dépendance fonctionnelle (DF) est une relation de détermination unique de valeurs.
Exemples :
- le nom et le prénom permettent d'identifier une seule personne détermine son age : nom+prenom --> age,
- le numéro de client détermine le nom du client : 4 --> Bloch mais 4 -X-> Monnet,
- le numéro de client détermine le prénom du client : 1 --> René mais 1 -X-> Jean.
L'une des propriétés (ou un groupe de propriétés) du concept permet d'identifier chaque donnée du concept qui séparément en dépendent. C'est l'identifiant' unique qui représente chaque groupe de valeurs des propriétés du concept.
Exemple oui :
- (dans notre table) le nom détermine le prénom : il peut être candidat identifiant. Cependant, il pourrait exister des homonymes
- le nom et le prénom déterminent la ville : le couple (nom, prenom) est candidat identifiant. Même remarque que ci-dessus.
- le numéro déternine à lui seul chaque champ de la table. Le numéro est le candidat le plus certain car il est unique pour chaque personne et qu'il détermine indémendament chaque donnée du concept.
Exemple non :
- le prénom ne détermine pas le nom, il ne peut être identifiant : Jean -> Rostand et Monnet : plusieurs valeurs
- le nom de ville ne détermine pas la personne, il ne peut être identifiant : Strasbourg -> plein de personnes
Une dépendance fonctionnelle est une relation
- non réversible (elle ne va que dans un seul sens) si a->b, b ne détermine pas forcément a
- transitive : si a->b et b->c alors a->c
Le graphe des dépendances fonctionnelles
Si cette étape n'est pas obligatoire, elle facilite fortement la compréhension et la création du modèle de données. Donc ... Allons-y.
À partir des dépendances fonctionnelles individuelles, on peut construire un schéma qui les représente.
Reprendre le dictionnaire des données et représenter chacune d'entre elle sur le graphe des dépendances fontionnelles pouis les relier avec des flèches qui représentent les dépendances.
Exemple
Soit le dictionnaire des données d'une gestion commerciale simple (contexte Gescom), les dépendances trouvées sont :
- le numéro de client détermine un et un seul nom de client. Chaque nom de client synonyme est déterminé par son propre numéro de client : 1=>Albator, 2=>Surcouf, 3=>Barberousse, 4=>Barberousse, 5=>Long John Silver ; les 3 et 4 sont deux client différents ayant le même nom.
- le numéro du client détermine la ville du client : 1=>Arcadia, 2=>Saint Malo, 3=>Alger, 4=>Bristol, 5=>Hispaniola ; on voit que pour 3 et 4 ce ne sont pas les mêmes villes. 3 et 4 sont donc des clients différents.
- le numéro de la commande détermine un et un seul client, celui qui a passé la commande.
- le couple numéro de la commande associé au code article, détermine la quantité d'article présent dans la commande.
- etc ...
Dictionnaire et dépendances directes (de la source vers la cible) :
Dépendances simples :
| nom |
description |
détermine un et un seul |
| addresse |
adresse du client |
-rien- |
| codeArt |
code de l'article |
description, qtéDispo, prixUnHT |
| dateCde |
date de la commande |
-rien- |
| description |
description de l'article |
-rien- |
| noCde |
numéro de commande |
noClient, dateCde |
| noClient |
numéro du client |
nom, adresse, ville, pays |
| nomClient |
nom du client |
-rien- |
| prixUnHT |
prix de vente unitaire hors taxe |
-rien- |
| qtéDispo |
quantité de l'article disponible à la vente |
-rien- |
| qtéEmp |
quantité de l'article commandé dans la commande |
(*) |
Dépendances complexe :
| de |
vers |
description |
| noCde + codeArt |
qteEmp |
quantité de l'article commandé dans la commande |
Graphe des dépendances :
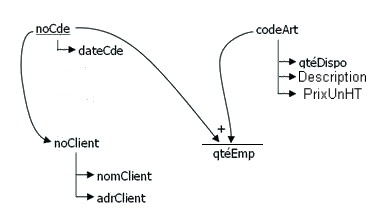
On peut maintenant facilement passer à la modélisation des données.