Introduction
Afin de comprendre les enjeux de ce cours, il faut avoir parcouru celui sur la réplication de données.
Ce cours concerne la répartition de charge entre deux serveurs web.
La petite histoire
Il était une fois une base de données qui devait être sauvegardée sur un réplica.
<< - Ouais, quelle galère, du SQL, encore du SQL, toujours du SQL ! Pffff. - Pffff ? Ne recommence pas, s'il te plait ! - Ben, tu ne trouve pas ça terrible, le SQL ? - Ben non, c'est juste utile d'avoir une sauvegarde de la base de données sans devoir gérer le truc. Une fois que c'est en place, plus besoin d'y toucher. - Watch, v'là le chef ! ... - (chef) Dites les collègues, vous ne trouvez pas que c'est dommage d'avoir un réplica qui ne soit pas productif ? Avec l'augmentation des connexions, on pourrait le mettre en ligne, non ? Essayez voir de me trouver une solution afin de répartir les connexions sur les deux serveurs. Allez, au boulot ! - Pffff. - Ouais : Pffff. >>
Bon, la répartition est une très bonne solution pour réduire la charge individuelle de chaque serveur.
En plus, il existe des solutions très simples dans notre cas : HA Proxy
Cependant, la répartition n'est pas seulement visible dans le domaine des connexions au serveurs web. Il existe de multiples répartitions
Le cours sur la répartition va explorer rapidement plusieurs technlogies de répartition ...
Contextes
Les organisations sont très concernées par des répartitions de charges face à la montée en puissance des connexions.
Pas de nouveauté sur les organisations. Cependant, la répartition est un enjeu de sûreté du SI pour éviter les surcharges des serveurs, des accès aux services, tant du LAN vers internet que d'internet vers nos services en DMZ.
Pour le particulier, cela est moins important côté client, mais les entreprises doivent assurer une bonne capacité de connexion pour offrir des services fluides et largement disponibles
Personne n'admettrait que les grand serveurs afficheraient une page du type : Erreur 501 Erreur interne, service non disponible pour l'instant, réessayez plus tard.
Ah bon ? ça vous est arrivé ? avec les impôts ou parcoursup, la veille de l'échéance de paiment ou d'inscription ...
Contraintes
Ce phénomène est souvent dû à la limitation de la puissance des serveurs pour avoir un débit réseau correct, une capacité de traitement suffisante en charge, complexité des traitements (chiffrement, maintien des sessions, etc.).
OK, Cela touche essentiellement les service web (http)
Hélas, mettre des serveur en cluster n'est pas simple et l'évolution de la demande nécessite une scalabilité importante (augmentation de l'architecture en suivi de la charge, innovations soft et hard).
Besoins
Les besoins sont donc assez bien identifiés :
- Besoin de haute disponibilité
- Angl. : High Availability
- Garantire de service
- Réponse avec la répartition de charge
- Angl. : Load Balancing
- Distribuer le travail
- Répartir les connexions
Attention
Couche 3 ou 2 : pour le routage ou pour le switching. Mais il ne s'agit pas vraiment de ça ici.
Couche 5 et plus ...
DFS : ce n'est pas ça, même si je le détaille plus loin.
On est sur la redondance de machines, de services.
Ça entre dans les plans de reprise et de continuité d'activité (PRA, PCA) pour l'aspect de continuté du service en mode dégradé quand l'un des serveur/service redondant est en panne.

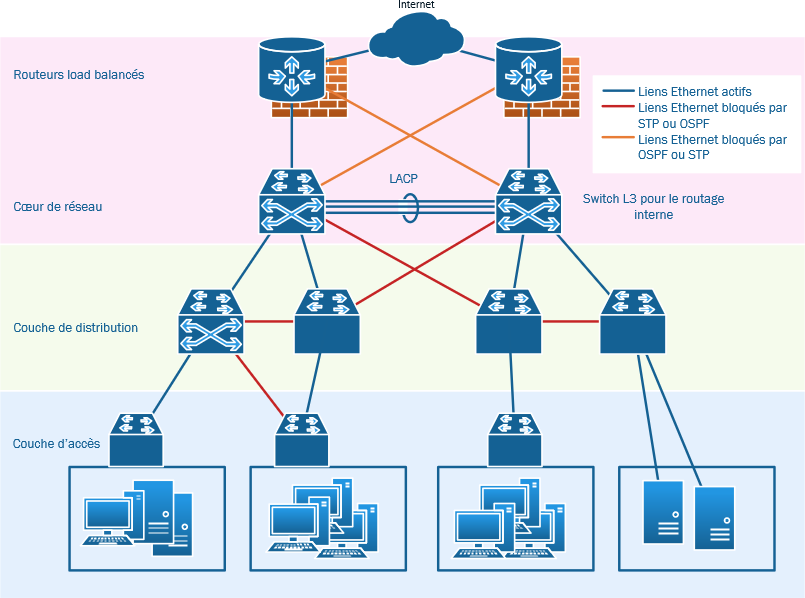
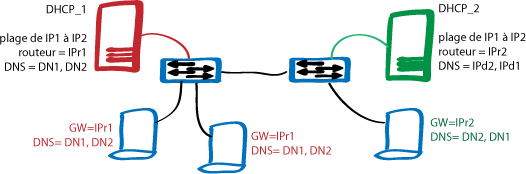
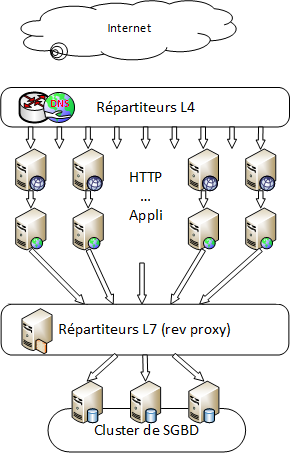
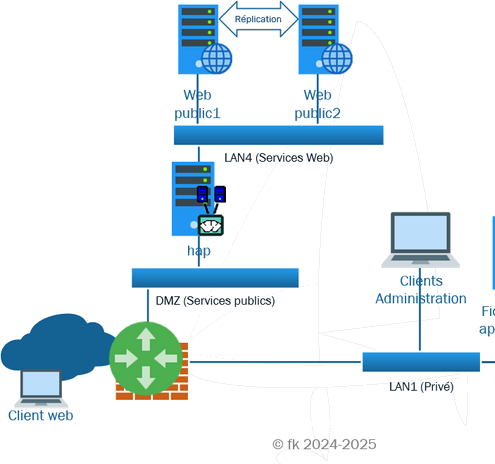
 Il permet ainsi à de multiples clients de se connecter vers l'extérieur, sur un même serveur distant et réduire l'occupation de bande passante sur le réseau internet et la charge de travail du dit serveur distant tout en accélérant les échanges :
Il permet ainsi à de multiples clients de se connecter vers l'extérieur, sur un même serveur distant et réduire l'occupation de bande passante sur le réseau internet et la charge de travail du dit serveur distant tout en accélérant les échanges :  On va donc charger un reverse proxy de conserver les pages les plus souvent demandées afin de décharger le serveur et accélérer les réponses aux clients.
On va donc charger un reverse proxy de conserver les pages les plus souvent demandées afin de décharger le serveur et accélérer les réponses aux clients. 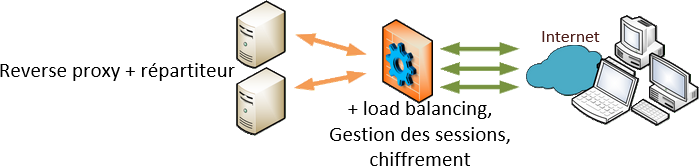 Le reverse proxy-répartiteur effecteus en plus de la répartition de charge sur des serveurs secondaires afin d'accélérer encore la réponse pour les données dynamiques.
Le reverse proxy-répartiteur effecteus en plus de la répartition de charge sur des serveurs secondaires afin d'accélérer encore la réponse pour les données dynamiques.